【微信小游戏直播】Android跨进程渲染推流实践
背景
近期,微信小游戏支持了视频号一键开播,将微信升级到最新版本,打开腾讯系小游戏(如跳一跳、欢乐斗地主等),在右上角菜单就可以看到发起直播的按钮一键成为游戏主播了:
微信小游戏出于性能和安全等一系列考虑,运行在一个独立的进程中,在该环境中不会初始化视频号直播相关的模块,这就意味着小游戏的音视频数据必须跨进程传输到主进程进行推流,给我们实现小游戏直播带来了一系列挑战。
视频采集推流
录屏采集?
小游戏直播本质上就是把主播手机屏幕上的内容展示给观众,自然而然地我们可以想到采用系统的录屏接口MediaProjection进行视频数据的采集,这种方案有这些优点:
- 系统接口,实现简单,兼容性和稳定性有一定保证
- 后期可以扩展成通用的录屏直播
- 对游戏性能影响较小,经测试对帧率影响在10%以内
- 可以直接在主进程进行数据处理及推流,不用处理小游戏跨进程的问题
这也是抖音采用的录屏直播方案,通用性比较强,可以直播包括但不限于游戏等内容: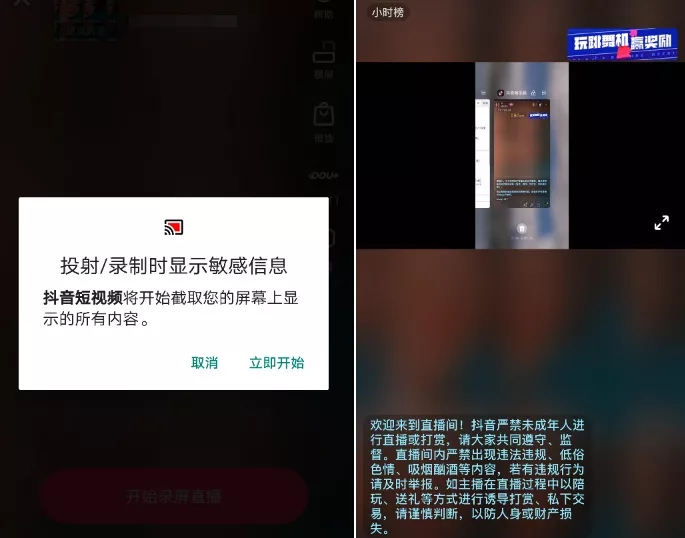
但是最终这个方案被否决了,主要出于以下考虑:
- 需要展示系统授权弹窗(如上图)
- 需要谨慎处理切出小游戏后暂停画面推流的情况,否则可能录制到主播的其他界面,有隐私风险
- 最关键的一点:产品设计上需要在小游戏上展示一个评论挂件(如下图),便于主播查看直播评论以及进行互动,录屏直播会让观众也看到这个组件,影响观看体验的同时会暴露一些只有主播才能看到的数据:

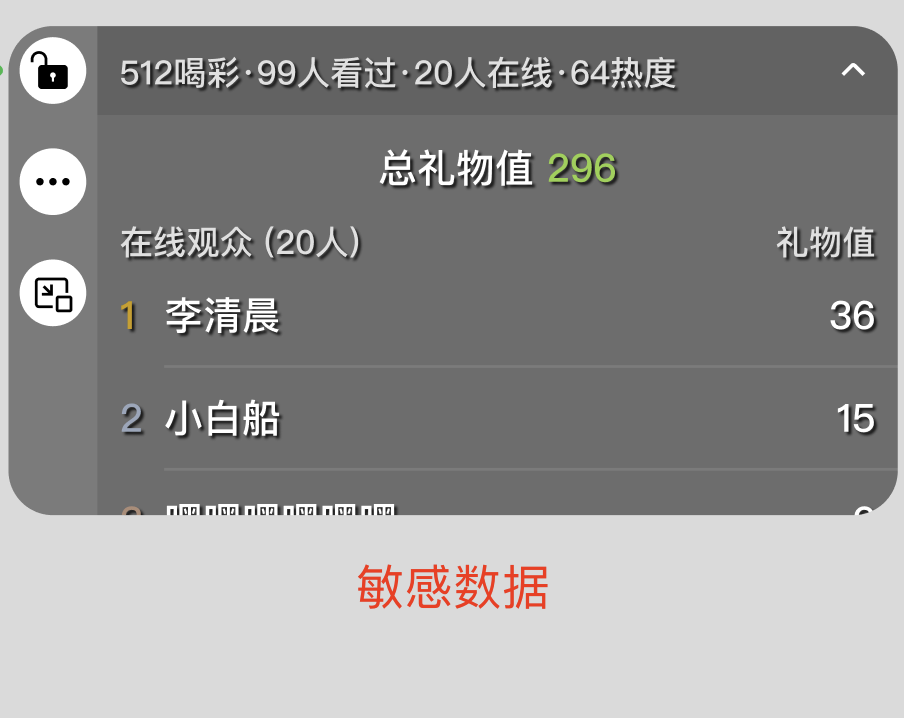
转念一想,既然小游戏的渲染完全是由我们控制的,为了更好的直播体验,能否将小游戏渲染的内容跨进程传输到主进程来进行推流呢?
小游戏渲染架构
为了更好地描述我们采用的方案,这里先简单介绍一下小游戏的渲染架构: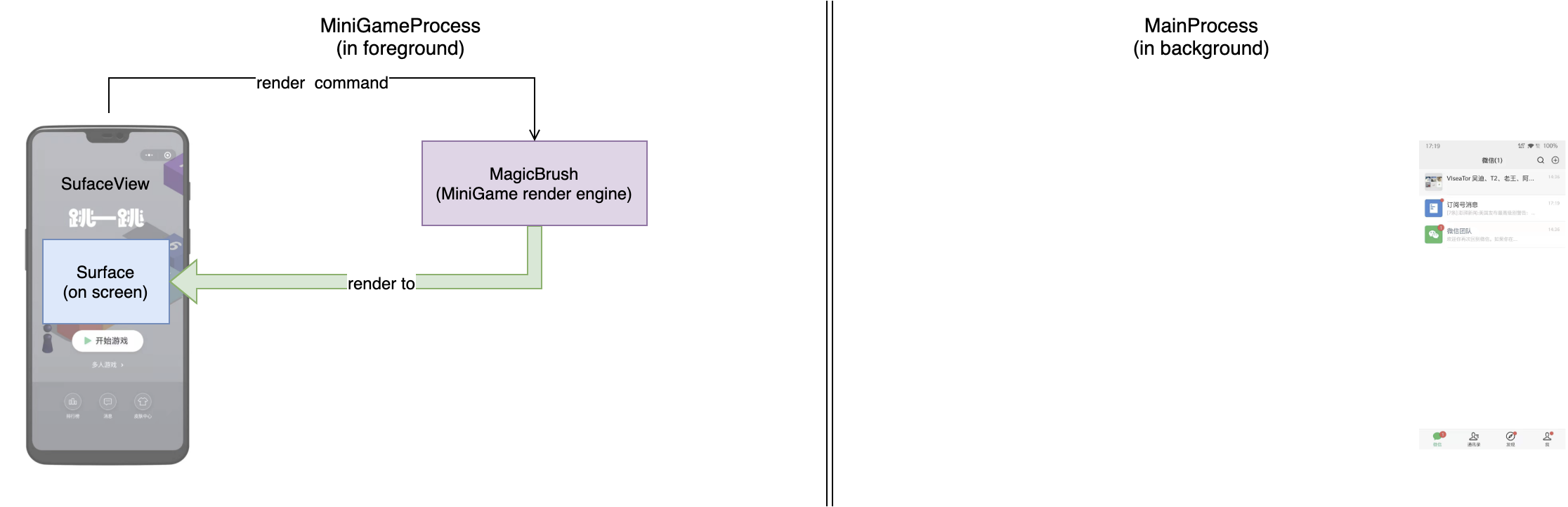
可以看到图中左半边表示在前台的小游戏进程,其中MagicBrush为小游戏渲染引擎,它接收来自于小游戏代码的渲染指令调用,将画面渲染到在屏的SurfaceView提供的Surface上。整个过程主进程在后台不参与。
小游戏录屏时的情况
小游戏之前支持过游戏内容的录制,和直播原理上类似,都需要获取当前小游戏的画面内容,录屏启用时小游戏会切换到如下的模式进行渲染:
可以看到,MagicBrush的输出目标不再是在屏的SurfaceView,而是Renderer产生的一个SurfaceTexture,这里先介绍一下Renderer的作用:
Renderer是一个独立的渲染模块,表示一个独立的GL环境,它可以创建SurfaceTexture作为输入,收到SurfaceTexture的onFrameAvailable方法将图像数据转换为类型是GL_TEXTURE_EXTERNAL_OES的纹理参与后续的渲染过程,并可以将渲染结果输出到另一个Surface上。
下面逐步对图中过程进行解释:
MagicBrush接收来自小游戏代码的渲染指令调用,将小游戏内容渲染到第一个Renderer所创建的SurfaceTexture上
- 随后这个
Renderer做了两件事情:
- 2.1 将得到的小游戏画面纹理再次渲染到了在屏的
Surface上 - 2.2 提供纹理
ID给到第二个Renderer(这里两个Renderer通过共享GLContext来实现共享纹理)
- 随后这个
- 第二个
Renderer将第一个Renderer提供的纹理渲染到mp4编码器提供的输入SurfaceTexture上,最终编码器编码产生mp4录屏文件
- 第二个
改造录屏方案?
可以看到,录屏方案中通过一个Renderer负责将游戏内容上屏,另一个Renderer将同样的纹理渲染到编码器上的方式实现了录制游戏内容,直播其实类似,是不是只要将编码器替换为直播的推流模块就可以了呢?
确实如此,但还缺少关键的一环:推流模块运行在主进程,我们需要实现跨进程传输图像数据!如何跨进程呢?
说到跨进程,可能我们脑海里蹦出的第一反应就是Binder、Socket、共享内存等等传统的IPC通信方法,但仔细一想,系统提供的SurfaceView是非常特殊的一个View组件,它不经过传统的View树来参与绘制,而是直接经由系统的SurfaceFlinger来合成到屏幕上,而SurfaceFlinger运行在系统进程上,我们绘制在SurfaceView所提供的Surface上的内容必然是可以跨进程进行传输的,而Surface跨进程的方法很简单——它本身就实现了Parcelable接口,这意味着我们可以用Binder直接跨进程传输Surface对象(原理可以参考链接)。于是我们有了下面这个初步方案:
可以看到,第3步不再是渲染到mp4编码器上,而是渲染到主进程跨进程传输过来的Surface上,主进程的这个Surface是通过一个Renderer创建的SurfaceTexture包装而来的,现在小游戏进程作为生产者向这个Surface渲染画面,当一帧渲染完毕后,主进程的SurfaceTexture就会收到onFrameAvailable回调通知图像数据已经准备完毕,随之通过updateTexImage获取到对应的纹理数据,这里由于直播推流模块只支持GL_TEXTURE_2D类型的纹理,这里主进程Renderer会将GL_TEXTURE_EXTERNAL_OES转换为GL_TEXTURE_2D纹理后给到直播推流编码器,完成推流过程。
经过一番改造,上述方案成功地实现了将小游戏渲染在屏幕上的同时传递给主进程进行推流,但这真的是最优的方案吗?思考一番,发现上述方案中的Renderer过多了,小游戏进程中存在两个,一个用于渲染上屏,一个用于渲染到跨进程而来的Surface上,主进程中还存在一个用于转换纹理以及调用推流模块。如果要同时支持录屏,还需要在小游戏进程再起一个Renderer用于渲染到mp4编码器,过多的Renderer意味着过多的额外渲染开销,会影响小游戏运行性能。
跨进程渲染方案
纵观整个流程,其实只有主进程的Renderer是必要的,小游戏所使用的额外Render无非就是想同时满足渲染上屏和跨进程传输,让我们大开脑洞——既然Surface本身就不受进程的约束,那我们干脆把小游戏进程的在屏Surface传递到主进程进行渲染上屏吧!
最终我们大刀阔斧地砍掉了小游戏进程的两个冗余Renderer,MagicBrush直接渲染到了跨进程传递而来的Surface上,而主进程的Renderer在负责纹理类型转换的同时也负责将纹理渲染到跨进程传递而来的小游戏进程的在屏Surface上,实现画面的渲染上屏。最终所需要的Renderer数量从原来的3个减少到了必要的1个,在架构更加清晰的同时提升了性能。
后续需要同时支持录屏时,只要稍作改动,将mp4编码器的输入SurfaceTexture也跨进程传递到主进程,再新增一个Renderer渲染纹理到它上面就行了:
兼容性与性能
到这里,不禁有点担心,跨进程传输和渲染Surface的这套方案的兼容性会不会有问题呢?实际上,虽然并不常见,但是官方文档里面是有说明可以跨进程进行绘制的:
SurfaceView combines a surface and a view. SurfaceView’s view components are composited by SurfaceFlinger (and not the app), enabling rendering from a separate thread/process and isolation from app UI rendering.
来源
并且Chrome以及Android O以后的系统WebView都有使用跨进程渲染的方案。
在我们的兼容性测试中,覆盖了Android 5.1及以后的各个主流系统版本和机型,除了Android 5.x机型上出现了跨进程渲染黑屏的问题外,其余均可以正常渲染上屏和推流。
性能方面,我们使用了webgl水族馆的Demo进行了性能测试,可以看到对于平均帧率的影响在15%左右,主进程的CPU因为渲染和推流有所升高,奇怪的是小游戏进程的CPU开销却出现了一些下降,这里下降的原因暂时还没有确认,怀疑与上屏操作移到主进程相关,也不排除是统计方法的影响。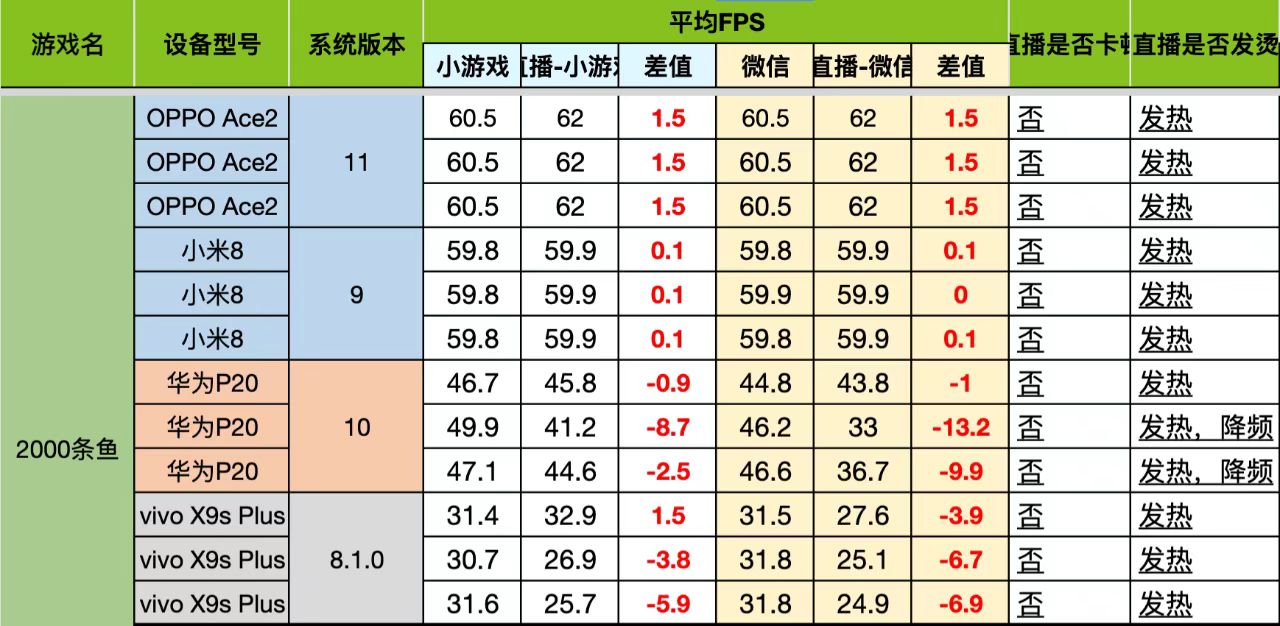
小结
为了实现不录制主播端的评论挂件,我们从小游戏渲染流程入手,借助于Surface跨进程渲染和传输图像的能力,把小游戏渲染上屏的过程移到了主进程,并同时生成纹理进行推流,在兼容性和性能上达到了要求。
音频采集推流
方案选择
在音频采集方案中,我们注意到在Android 10及以上系统提供了AudioPlaybackCapture方案允许我们在一定的限制内对系统音频进行采集,当时预研的一些结论如下:
捕获方 - 进行捕获的条件
- Android 10(api 29)及以上
- 获取了
RECORD_AUDIO权限 - 通过
MediaProjectionManager.createScreenCaptureIntent()进行MediaProjection权限的申请(和MediaProjection录屏共用) - 通过
AudioPlaybackCaptureConfiguration.addMatchingUsage()/AudioPlaybackCaptureConfiguration.excludeUsage()添加/排除要捕获的MEDIA类型 - 通过
AudioPlaybackCaptureConfiguration.addMatchingUid() /AudioPlaybackCaptureConfiguration.excludeUid()添加/排除可以捕获的应用的UID
被捕获方 - 可以被捕获的条件
Player的AudioAttributes设置的Usage为USAGE_UNKNOWN,USAGE_GAME或USAGE_MEDIA(目前绝大部分用的都是默认值,可以被捕获)- 应用的
CapturePolicy被设置为AudioAttributes#ALLOW_CAPTURE_BY_ALL,有三种办法可以设置(以最严格的为准,目前微信内没有配置,默认为可以捕获) - 通过
manifest.xml设置android:allowAudioPlaybackCapture="true",其中,TargetApi为29及以上的应用默认为true,否则为false - api 29及以上可以通过
setAllowedCapturePolicy方法运行时设置 - api 29及以上可以通过
AudioAttributes针对每一个Player单独设置
总的来说,Android 10及以上可以使用AudioPlaybackCapture方案进行音频捕获,但考虑到Android 10这个系统版本限制过高,最终我们选择了自己来采集并混合小游戏内播放的所有音频。
跨进程音频数据传输
现在,老问题又摆在了我们眼前:小游戏混合后的音频数据在小游戏进程,而我们需要把数据传输到主进程进行推流。
与一般的IPC跨进程通信用于方法调用不同,在这个场景下,我们需要频繁地(40毫秒一次)传输较大的数据块(16毫秒内的数据量在8k左右),同时,由于直播的特性,这个跨进程传输过程的延迟需要尽可能地低,否则就会出现音画不同步的情况。为了达到上述目标,我们对Binder、LocalSocket、MMKV、SharedMemory、Pipe这几种IPC方案进行了测试。在搭建的测试环境中,我们在小游戏进程模拟真实的音频传输的过程,每隔16毫秒发送一次序列化后的数据对象,数据对象大小分为3k/4M/10M三挡,在发送前储存时间戳在对象中;在主进程中接收到数据并完成反序列化为数据对象的时刻作为结束时间,计算传输延迟。最终得到了如下结果:
注:其中XIPCInvoker(Binder)和MMKV在传输较大数据量时耗时过长,不在结果中展示。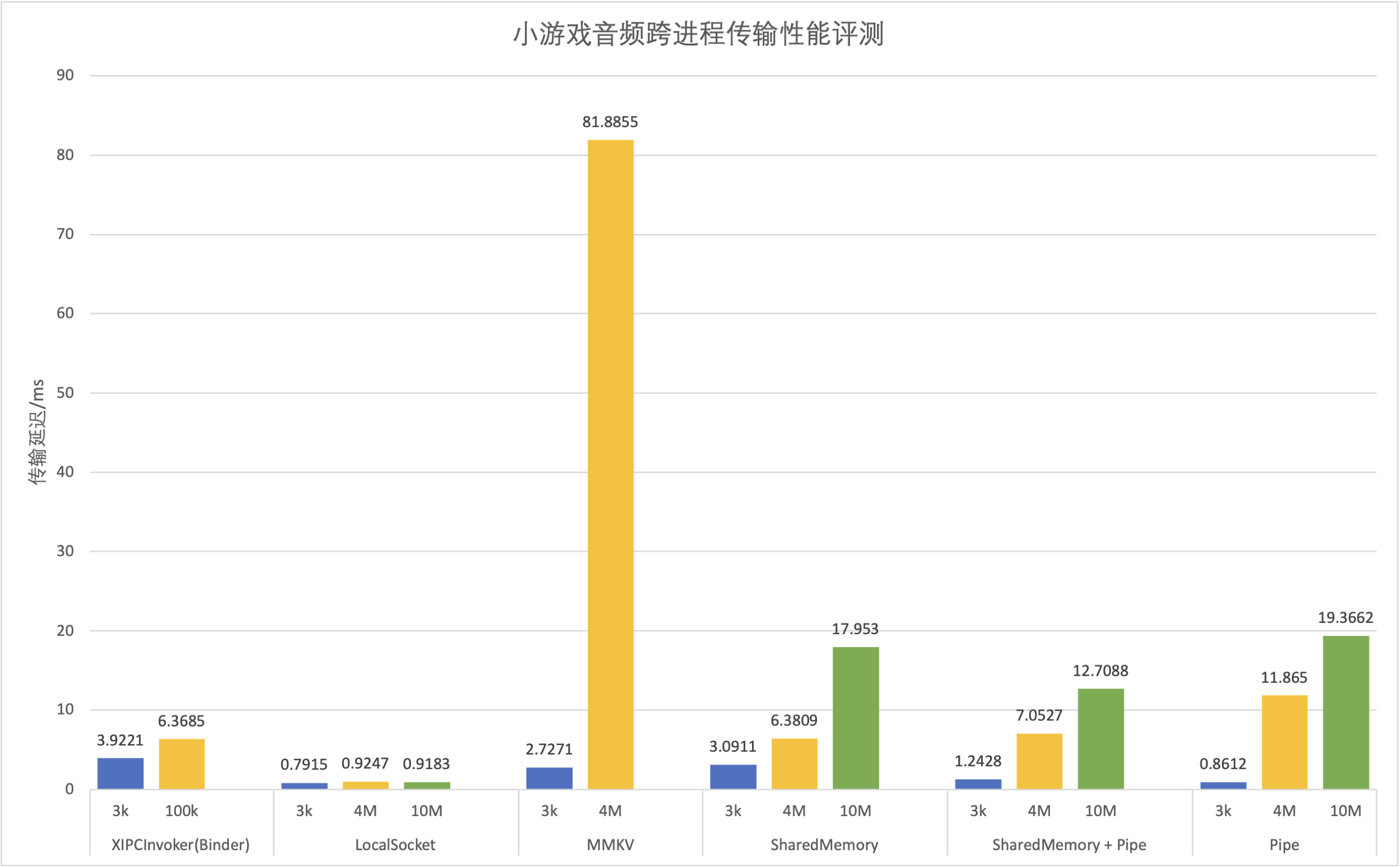
对于各个方案的分析如下(卡顿率表示延迟>2倍平均延迟且>10毫秒的数据占总数的比例):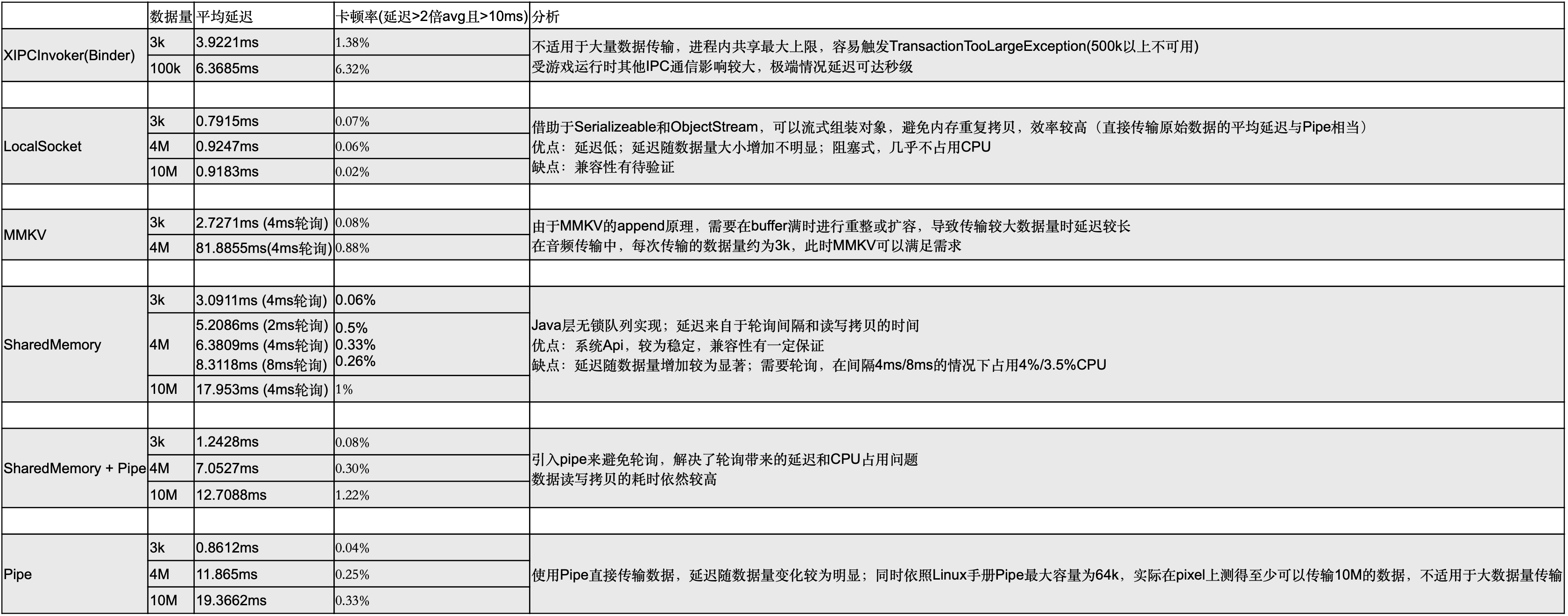
可以看到LocalSocket方案在各个情况下的传输延迟表现都极为优异,差异的原因主要是因为裸二进制数据在跨进程传输到主进程后,仍需要进行一次数据拷贝操作来反序列化为数据对象,而使用LocalSocket时可以借助于ObjectStream和Serializeable来实现流式的拷贝,相比与其他方案的一次性接收数据后再拷贝节约了大量的时间(当然其他方案也可以设计成分块流式传输同时拷贝,但实现起来有一定成本,不如ObjectStream稳定易用)。
我们也对LocalSocket进行了兼容性与性能测试,未出现不能传输或断开连接的情况,仅在三星S6上平均延迟超过了10毫秒,其余机型延迟均在1毫秒左右,可以满足我们的预期。
LocalSocket的安全性
常用的Binder的跨进程安全性有系统实现的鉴权机制来保证,LocalSocket作为Unix domain socket的封装,我们必须考虑它的安全性问题。
论文The Misuse of Android Unix Domain Sockets and Security Implications较为详细地分析了Android中使用LocalSocket所带来的安全风险,总结论文所述:由于LocalSocket本身缺乏鉴权机制,任意一个应用都可以进行连接,从而截取到数据或是向接收端传递非法数据引发异常。针对这个特点,我们可以做的防御方法有两种:
- 随机化
LocalSocket的命名,例如使用当前直播的小游戏的AppId和用户uin等信息计算md5作为LocalSocket的名字,使得攻击者无法通过固定或穷举名字的方法尝试建立连接 - 引入鉴权机制,在连接成功后发送特定的随机信息来验证对方的真实性,然后才启动真正的数据传输
小结
为了兼容Android 10以下的机型也能直播,我们选择自己处理小游戏音频的采集,并通过对比评测,选用了LocalSocket作为跨进程音频数据传输的方案,在延迟上满足了直播的需求。同时,通过一些对抗措施,可以有效规避LocalSocket的安全风险。
多进程带来的问题
回头来看,虽然整个方案看起来比较通顺,但是在实现的过程中还是由于多进程的原因踩过不少坑,下面就分享其中两个比较主要的。
glFinish造成渲染推流帧率严重下降
在刚实现跨进程渲染推流的方案后,我们进行了一轮性能与兼容性测试,在测试中发现,部分中低端机型上帧率下降非常严重: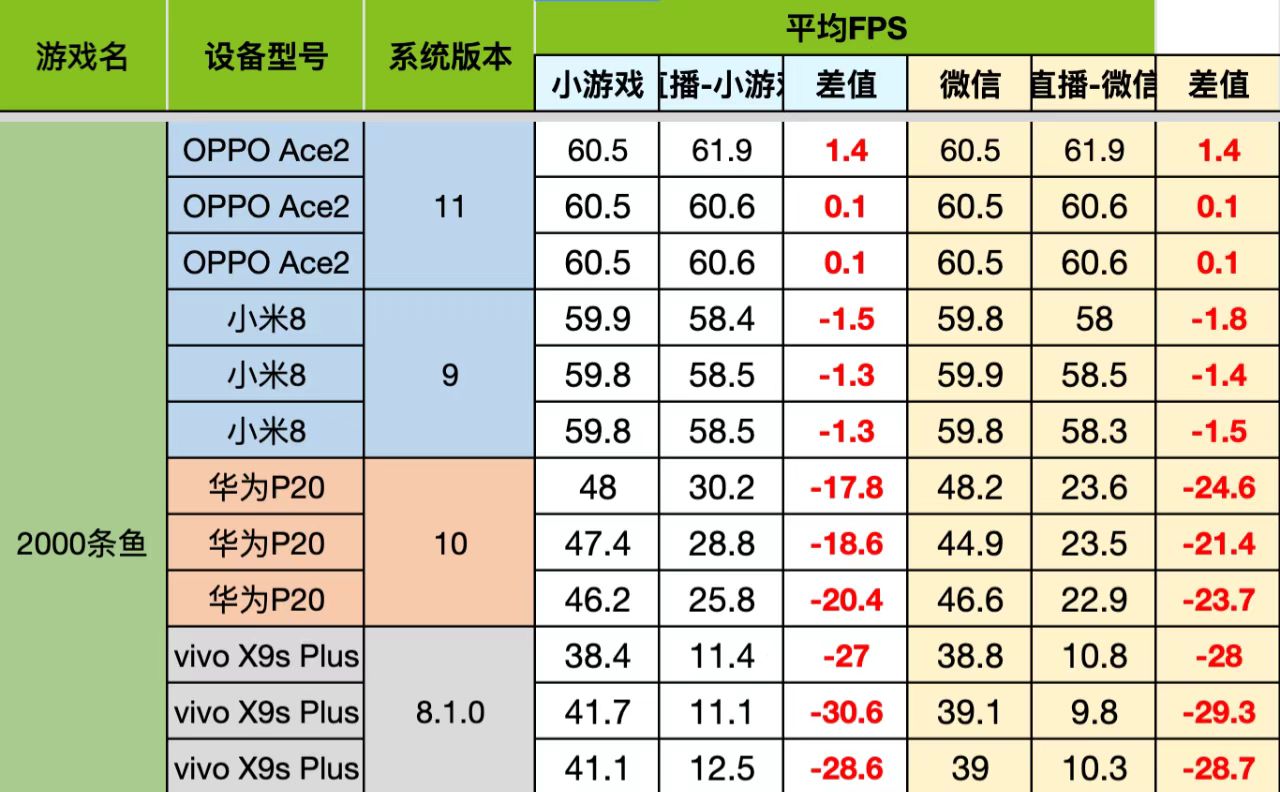
复现后查看小游戏进程渲染的帧率(即小游戏进程绘制到跨进程而来的Surface上的帧率)发现可以达到不开直播时的帧率,而我们所用的测试软件PerfDog所记录的是在屏Surface的绘制帧率,这就说明性能下降不是直播开销过高引起的小游戏代码执行效率下降,而是主进程上屏Renderer效率太低。
于是我们对主进程直播时运行效率进行了Profile,发现耗时函数为glFinish,并且有两次调用,第一次调用是Renderer将外部纹理转2D纹理时,耗时会达到100多毫秒;第二次调用是腾讯云直播SDK内部,耗时10毫秒以内。如果将第一次调用去掉,直播SDK内部的这次则会耗时100多毫秒。为了弄清为什么这个GL指令耗时这么久,我们先看看它的描述:
glFinishdoes not return until the effects of all previously called GL commands are complete.
来源
描述很简单,它会阻塞直到之前调用的所有GL指令全部完成,这么看来是之前的GL指令太多了?但是GL指令队列是以线程为维度隔离的,在主进程的Renderer线程中,glFinish前只会执行纹理类型转换的非常少量的GL指令,和腾讯云的同学了解到推流接口也不会在本线程执行很多GL指令,如此少量的GL指令怎么会使glFinish阻塞这么久呢?等等,大量GL指令?小游戏进程此时不就正在执行大量GL指令吗,难道是小游戏进程的大量GL指令导致了主进程的glFinsih耗时过长?这样的猜测不无道理,虽然GL指令队列是按线程隔离的,但处理指令的GPU只有一个,一个进程的GL指令过多导致另一个进程在需要glFinish时阻塞过久。Google了一圈没找到有相关的描述,需要自己验证这个猜测。
重新观察一遍上面的测试数据,发现直播前能达到60帧的情况下,直播后也能达到60帧左右,这是不是就说明在小游戏的GPU负载较低时glFinish的耗时也会下降呢?在性能下降严重的机型上,控制其他变量不变尝试运行低负载的小游戏,发现glFinsih的耗时成功下降到了10毫秒左右,这就印证了上面的猜测——确实是小游戏进程正在执行的大量GL指令阻塞了主进程glFinish的执行。
该如何解决呢?小游戏进程的高负载无法改变,那能让小游戏在一帧渲染完成以后停住等主进程的glFinish完成后再渲染下一帧吗?这里经过了各种尝试,OpenGL的glFence同步机制无法跨进程使用;由于GL指令是异步执行的,通过跨进程通信加锁锁住小游戏的GL线程并不能保证主进程执行glFinish时小游戏进程的指令已经执行完,而能保证这点只有通过给小游戏进程加上glFinish,但这会使得双缓冲机制失效,导致小游戏渲染帧率的大幅下降。
既然glFinish所带来的阻塞无法避免,那我们回到问题的开始——为什么需要glFinish?由于双缓冲机制的存在,一般来说并不需要glFinish来等待之前的绘制完成,否则双缓冲就失去了意义。两次glFinish中,第一次纹理处理的调用可以直接去掉,第二次腾讯云SDK的调用经过沟通,发现是为了解决一个历史问题引入的,可以尝试去掉。在腾讯云同学的帮助下,去掉glFinish后,渲染的帧率终于和小游戏输出的帧率一致,经过兼容性和性能测试,没有发现去掉glFinish带来的问题。
这个问题最终的解法很简单,但分析问题原因的过程实际上做了非常多的实验,同一个应用中一个高GPU负载的进程会影响到另一个进程的glFinish耗时的这种场景确实也非常少见,能参考的资料不多。这个过程也让我深刻体会到了glFinish使得双缓冲机制失效所带来的性能影响是巨大的,在使用OpenGL进行渲染绘制时对于glFinish的使用应当非常谨慎。
后台进程优先级问题
在测试过程中,我们发现无论以多少的帧率向直播SDK发送画面,观众端看到的画面帧率始终只有16帧左右,排除后台原因后,发现是编码器编码的帧率不足导致的。经腾讯云同学测试同进程内编码的帧率是可以达到设定的30帧的,那么说明还是多进程带来的问题,这里编码是一个非常重的操作,需要消耗比较多的CPU资源,所以我们首先怀疑的就是后台进程优先级的问题。
为了确认问题,我们找来了已经root的手机,通过chrt命令提高编码线程的优先级,观众端帧率立马上到了25帧;另一方面,经测试如果在小游戏进程上显示一个主进程的浮窗(使主进程具有前台优先级),帧率可以上到30帧。综上,可以确认帧率下降就是由于后台进程(以及其拥有的线程)的优先级过低导致的。
提高线程优先级的做法在微信里比较常见,例如小程序的JS线程以及小游戏的渲染线程都会在运行时通过android.os.Process.setThreadPriority方法设置线程的优先级。腾讯云SDK的同学很快提供了接口供我们设置线程优先级,但当我们真正运行起来时,却发现编码的帧率仅从16帧提高到了18帧左右,是哪里出问题了呢?
前面提到,我们通过chrt命令设置线程优先级是有效的,但android.os.Process.setThreadPriority这个方法设置的线程优先级对应的是renice这个命令设置的nice值。仔细阅读chrt的manual后,发现之前测试时的理解有误,之前直接用chrt -p [pid] [priority]的命令设置优先级,却没有设置调度策略这个参数,导致该线程的调度策略从Linux默认的SCHED_OTHER改为了命令缺省设置的SCHED_RR,而SCHED_RR是一种“实时策略”,导致线程的调度优先级变得非常高。
实际上,通过renice(也就是android.os.Process.setThreadPriority)设置的线程优先级,对于后台进程所拥有线程来说没有太大的帮助。其实早有人解释过这一点:
To address this, Android also uses Linux cgroups in a simple way to create more strict foreground vs. background scheduling. The foreground/default cgroup allows thread scheduling as normal. The background cgroup however applies a limit of only some small percent of the total CPU time being available to all threads in that cgroup. Thus if that percentage is 5% and you have 10 background threads all wanting to run and one foreground thread, the 10 background threads together can only take at most 5% of the available CPU cycles from the foreground. (Of course if no foreground thread wants to run, the background threads can use all of the available CPU cycles.)
来源
最终,为了提高编码帧率并防止后台主进程被杀,我们最终还是决定直播时在主进程创建一个前台Service。
总结与展望
多进程是一把双刃剑,在给我们带来隔离性和性能优势的同时也带来了跨进程通信这一难题,所幸借助系统Surface的能力和多种多样的跨进程方案可以较好地解决小游戏直播中所遇到的问题。当然解决跨进程问题最好的方案是避免跨进程,我们也考虑了将视频号直播的推流模块运行在小游戏进程的方案,但出于改造成本的考虑而没有选择这一方案。
同时,这次对于SurfaceView跨进程渲染的实践也对其他业务有一定参考价值:对于一些内存压力较大或是安全风险较高,又需要进行SurfaceView渲染绘制的场景,可以把逻辑放到独立的进程,再通过跨进程渲染的方式绘制到主进程的View上,在获得独立进程优势的同时又避免了进程间跳转所带来的体验的割裂。